
티스토리 뷰
Codeforces에 올린 글을 보관 목적으로 블로그에도 올립니다.
Yesterday I participated in a local contest involving a problem about Monge arrays. I could've wrote some d&c optimization, but I got bored of typing it so I copypasted maroonrk's SMAWK implementation to solve it. Today, I somehow got curious about the actual algorithm, so here it goes.
1. Definition
I assume that the reader is aware of the concept of D&C Optimization and Monge arrays.
The goal of SMAWK is to compute the row optima (ex. row minima or maxima...) in a $n \times m$ totally monotone matrix. By totally monotone, it means the following:
Def: Monotone. The matrix is monotone if the position of row optima is non-decreasing.
Def: Totally Monotone (TM). The matrix is totally monotone if every $2 \times 2$ submatrix is monotone.
Totally monotone matrices are monotone (proof easy but nontrivial), but not vice versa. The latter is a stronger condition. Note that Divide and Conquer Optimization works on a monotone matrix, therefore if you can use SMAWK, you can always use D&C Optimization, but maybe not vice versa. I think it's a niche case, though.
If you want to compute the row minima of a matrix, the TM condition holds iff for all columns $p < q$:
- If $A[i][p] > A[i][q]$ then $A[i + 1][p] > A[i + 1][q]$
- If $A[i][p] = A[i][q]$ then $A[i + 1][p] \geq A[i + 1][q]$
The takeaway is that if you took $(i, q)$ as the optimum, then $(i + 1, p)$ should not be an optimum. At first, I was very confused on the maximum and minimum, but the definition of TM is independent of them. There is absolutely no reason to be confused. On the other hand, sometimes the row optima is non-increasing. You should be careful for that case. The solution is to reverse all rows.
For all columns $p < q$, if the matrix is TM (per row minima), then if you read columns from top to the bottom you have:
- rows with $A[i][p] < A[i][q]$
- rows with $A[i][p] = A[i][q]$
- rows with $A[i][p] > A[i][q]$
On the other hand, if the matrix is Monge, $A[i][p] - A[i][q]$ is nondecreasing, therefore:
- Monge matrix is TM.
- Transpose of Monge matrix is Monge and also TM. (Transpose of TM may not TM.)
- You can compute both row optima and column optima in Monge arrays.
2. Algorithm
Basically, SMAWK is a combination of two independent algorithms: Reduce and Interpolate. Let's take a look at both algorithms.
Interpolate
This is the easy one. We can solve $n = 1$ case naively, so assume $n \geq 2$. The algorithm works as follows:
- Take all odd rows and remove all even rows.
- Recursively solve for odd rows.
- Let $opt(i)$ be the optimal position for row $i$. We have $opt(2k-1) \le opt(2k) \le opt(2k+1)$, so brute-force all candidates for $[opt(2k-1), opt(2k+1)]$.
For each even rows, we need $opt(2k+1) - opt(2k-1) + 1$ entries to determine the answer. Summing this, we have $T(n, m) = O(n + m) + T(n / 2, m)$. This looks ok for $n > m$, but for $n < m$ it doesn't look like a good approach.
Reduce
This is the harder one, but not too hard. Say that we have queries two values $A[r][u], A[r][v]$ for $u < v$. Depending on the comparison, you have the following cases:
- $A[r][u] \le A[r][v]$. In this case, $A[r][v]$ is not a candidate for row minima, and consequently for all $A[r - 1][v], A[r - 2][v], \ldots, A[1][v]$.
- $A[r][u] > A[r][v]$. In this case, $A[r][u]$ is not a candidate for row minima, and consequently for all $A[r + 1][u], A[r + 2][u], \ldots, A[n][u]$.
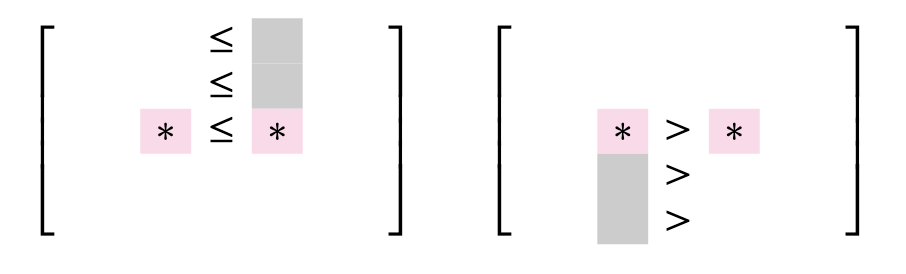
Let's further proceed with this information. We scan each column from left to right. For each column, we compare it's entries in the first row. We either have
- $A[1][u] \le A[1][v]$. In this case, $A[1][v]$ is not a candidate for row minima.
- $A[1][u] > A[1][v]$. In this case, the whole column $u$ is useless.
In the second case, we are very lucky — we can remove the whole column! On the other hand, the first case only rules out a single candidate. Let's maintain a stack to maintain all non-useless columns, so we store the first column and move on. If we compare the entries in the second row, we either have
- $A[2][u] \le A[2][v]$. In this case, $A[1][v], A[2][v]$ is not a candidate for row minima.
- $A[2][u] > A[2][v]$. In this case, the whole column $u$ except the first row is useless. But we declared $A[1][u]$ to be useless before, therefore the whole column $u$ is useless again.
Repeating this, we have the following very simple algorithm:
for (int i = 1; i <= m; i++) {
while (!stk.empty() && A[stk.size()][stk.back()] > A[stk.size()][i])
stk.pop_back();
if (stk.size() < n)
stk.push_back(i);
}That's it! As a result, we can reduce the number of columns to at most the number of rows in $O(n + m)$ time.
Putting it all together
Now we are ready to present the whole algorithm, and it's so simple:
- Reduce to make $n \geq m$ in $O(n + m)$ time.
- Interpolate to halve $n$ in $O(n)$ time.
- Recursively continue.
What is the time complexity? Except for the very first iteration of SMAWK, we can assume that the size of row and column is roughly the same. Then, we spend $O(n)$ time to halve the size of rows and columns, therefore the time complexity is $O(n + m)$.
3. Implementation
I implemented the above algorithm, which was actually pretty easy: It's not simpler than D&C optimization (since it's very very simple), but I thought it was pretty pleasant to implement. Then I submitted this nice faster linear-time alternatives to the template D&C optimization problems... and got Time Limit Exceeded, because:
- My implementation was not that optimized
- D&C optimization has super low constant and likely works better on random tests
- Whereas SMAWK is... well, not that constant heavy, but not so good either.
Then I just decided to copy-paste maroonrk's SMAWK implementation (I copied it from here), which I'm not sure if it's the fastest, but looks to have some constant optimizations, and was about 2x faster than my implementation. In the online judges, it seemed a little (1.5x?) faster than the D&C optimization for $N = 200000$.
But it's not faster or simpler than D&C, why should I learn it? I mean, like ad-hoc problems, you don't always do stuff because there is a particular reason to do it, so...
4. Conclusion
- SMAWK is simpler than I thought.
- SMAWK is faster than D&C if $N$ is near some million.
- SMAWK is slower than D&C if $N$ is near some thousand.
- If you are afraid of missing some AC because of not knowing this algorithm, probably you don't have to.
- Just like the one in practice problem, somebody can ask you to use only $4(n+m)$ matrix oracle calls or so, not all is lost...
By the way, it is well-known to compute $DP[i] = \min_{j} DP[j] + Cost(j + 1, i)$ in $O(n \log n)$ time if the cost is Monge. Normal SMAWK can't optimize this, but it seems there is a variant of SMAWK named LARSCH algorithm which computes this sort of recurrences in $O(n)$ time. I mean, just so you know...
Practice problems??
References
'공부 > Problem solving' 카테고리의 다른 글
| 구간 최장 증가 부분 수열 쿼리 (Part 1) (0) | 2023.01.27 |
|---|---|
| Suffix Automaton (0) | 2023.01.08 |
| Good Bye 2022 짧은 후기 (0) | 2022.12.31 |
| 2022.12.18 problem solving (0) | 2022.12.18 |
| Segment Tree Beats와 Kinetic Segment Tree (0) | 2022.12.04 |
- Total
- Today
- Yesterday